沙诺 Blog
Happy coding
shanuo
分类
最新评论
最新留言
链接
RSS
功能
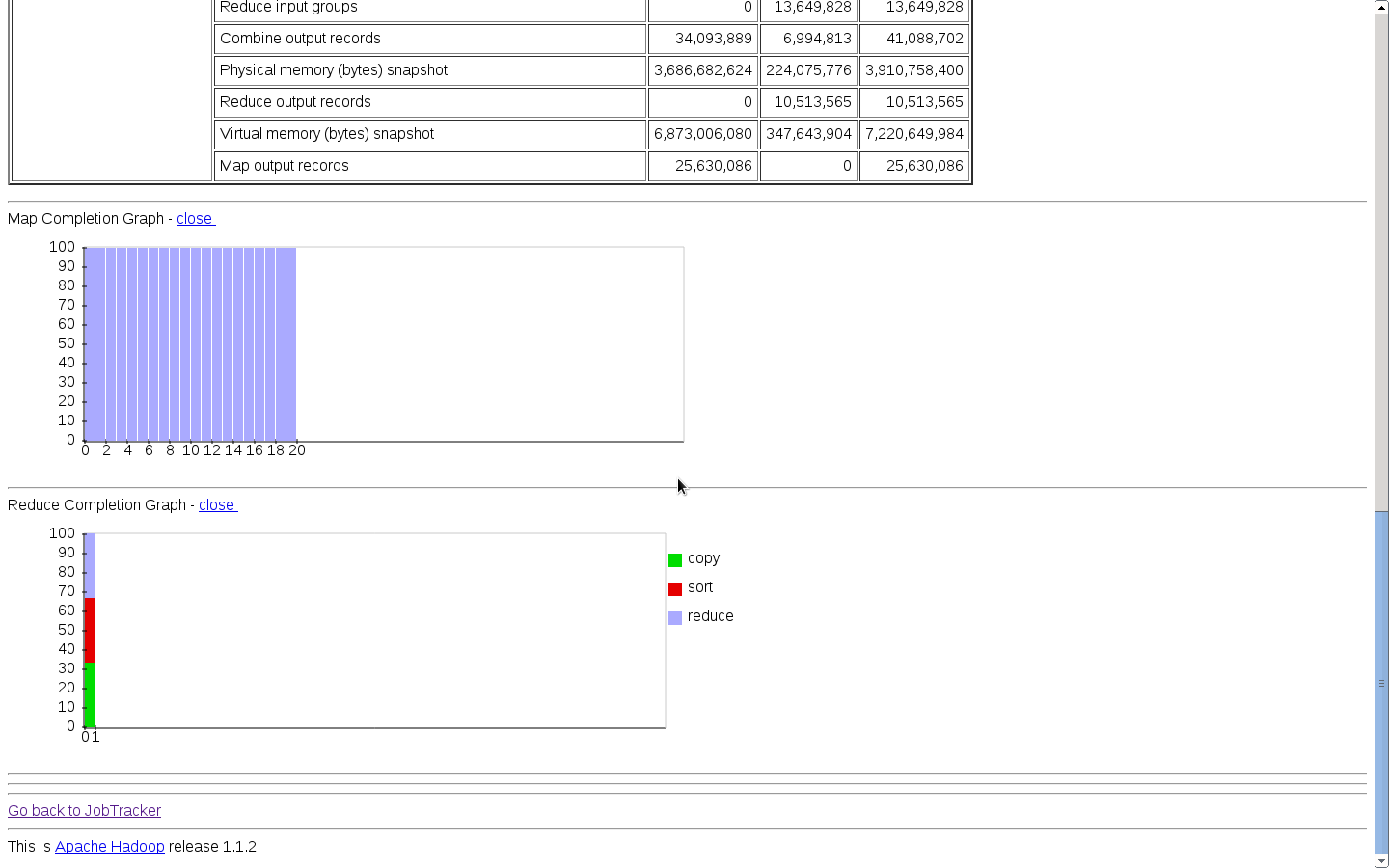
hadoop运行mahout的贝叶斯
mahout运行bayes(贝叶斯)算法的前提条件:
(1)启动hadoop
hadoop@master:~$ start-all.sh
(2)成功编译mahout源码
hadoop@master:~$ cd $MAHOUT_HOME
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mvn install -Dmaven.test.skip=true
mahout运行bayes(贝叶斯)算法的步骤:
(1)生成input的数据
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mahout org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups -p /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-data/20news-bydate/20news-bydate-train -o /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-result/bayes-train-input -a org.apache.mahout.vectorizer.DefaultAnalyzer -c UTF-8
运行结果:
Running on hadoop, using HADOOP_HOME=/home/hadoop/cloud/hadoop-1.0.4
HADOOP_CONF_DIR=/home/hadoop/cloud/confDir/hadoop/conf
Warning: $HADOOP_HOME is deprecated.
13/08/09 14:07:09 WARN driver.MahoutDriver: No org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups.props found on classpath, will use command-line arguments only
13/08/09 14:07:14 INFO driver.MahoutDriver: Program took 5202 ms
(2)生成test的数据
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mahout org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups -p /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-data/20news-bydate/20news-bydate-test -o /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-result/bayes-test-input -a org.apache.mahout.vectorizer.DefaultAnalyzer -c UTF-8
运行结果:
Running on hadoop, using HADOOP_HOME=/home/hadoop/cloud/hadoop-1.0.4
HADOOP_CONF_DIR=/home/hadoop/cloud/confDir/hadoop/conf
Warning: $HADOOP_HOME is deprecated.
13/08/09 14:13:35 WARN driver.MahoutDriver: No org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups.props found on classpath, will use command-line arguments only
13/08/09 14:13:38 INFO driver.MahoutDriver: Program took 3428 ms
(3)将训练文本集上传到HDFS上
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ hadoop dfs -put /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-result/bayes-train-input/ bayes-train-input
(4)模型训练:依据训练文本集来训练贝叶斯分类器模型
解释一下命令:-i:表示训练集的输入路径,HDFS路径; -o:分类模型输出路径; -type:分类器类型,这里使用bayes,可选cbayes;
-ng:(n-gram)建模的大小,默认为1; -source:数据源的位置,HDFS或HBase
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mahout trainclassifier -i bayes-train-input -o bayes-newsmodel -type bayes -ng 1 -source hdfs
(5)将测试文本集上传到HDFS上
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ hadoop dfs -put /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-result/bayes-test-input/ bayes-test-input
(6)模型测试:依据训练的贝叶斯分类器模型来进行分类测试
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mahout testclassifier -m bayes-newsmodel -d bayes-test-input -type bayes -ng 1 -source hdfs -method mapreduce
运行结果(与apache官网里面的一致):
13/08/09 14:56:34 INFO bayes.BayesClassifierDriver: =======================================================
Confusion Matrix
-------------------------------------------------------
a b c d e f g h i j k l m n o p q r s t u <--Classified as
381 0 0 0 0 9 1 0 0 0 1 0 2 0 0 1 0 0 3 0 0 | 398 a = rec.motorcycles
1 284 0 0 0 0 1 0 6 3 11 0 3 66 0 1 6 0 4 9 0 | 395 b = comp.windows.x
2 0 339 2 0 3 5 1 0 0 0 0 1 1 12 1 7 0 2 0 0 | 376 c = talk.politics.mideast
4 0 1 327 0 2 2 0 0 2 1 1 5 0 1 4 12 0 2 0 0 | 364 d = talk.politics.guns
7 0 4 32 27 7 7 2 0 12 0 0 0 6 100 9 7 31 0 0 0 | 251 e = talk.religion.misc
10 0 0 0 0 359 2 2 0 1 3 0 6 1 0 1 0 0 11 0 0 | 396 f = rec.autos
0 0 0 0 0 1 383 9 1 0 0 0 0 0 0 0 0 0 3 0 0 | 397 g = rec.sport.baseball
1 0 0 0 0 0 9 382 0 0 0 0 1 1 1 0 2 0 2 0 0 | 399 h = rec.sport.hockey
2 0 0 0 0 4 3 0 330 4 4 0 12 5 0 0 2 0 12 7 0 | 385 i = comp.sys.mac.hardware
0 3 0 0 0 0 1 0 0 368 0 0 4 10 1 3 2 0 2 0 0 | 394 j = sci.space
0 0 0 0 0 3 1 0 27 2 291 0 25 11 0 0 1 0 13 18 0 | 392 k = comp.sys.ibm.pc.hardware
8 0 1 109 0 6 11 4 1 18 0 98 3 1 11 10 27 1 1 0 0 | 310 l = talk.politics.misc
6 0 1 0 0 4 2 0 5 2 12 0 321 8 0 4 14 0 8 6 0 | 393 m = sci.electronics
0 11 0 0 0 3 6 0 10 7 11 0 13 298 0 2 13 0 7 8 0 | 389 n = comp.graphics
2 0 0 0 0 0 4 1 0 3 1 0 1 3 372 6 0 2 1 2 0 | 398 o = soc.religion.christian
4 0 0 1 0 2 3 3 0 4 2 0 12 7 6 342 1 0 9 0 0 | 396 p = sci.med
0 1 0 1 0 1 4 0 3 0 1 0 4 8 0 2 369 0 1 1 0 | 396 q = sci.crypt
10 0 4 10 1 5 6 2 2 6 2 0 1 2 86 15 14 152 0 1 0 | 319 r = alt.atheism
4 0 0 0 0 9 1 1 8 1 12 0 6 3 0 2 0 0 341 2 0 | 390 s = misc.forsale
8 5 0 0 0 1 6 0 8 5 50 0 2 39 1 0 9 0 3 257 0 | 394 t = comp.os.ms-windows.misc
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | 0 u = unknown
Default Category: unknown: 20
13/08/09 14:56:34 INFO driver.MahoutDriver: Program took 118128 ms
这一篇是转的,上一篇是自己写的,但是自己写的中间过程不完整,所以又转了一篇。
Git常用命令
1) 远程仓库相关命令
检出仓库:$ git clone git://github.com/jquery/jquery.git
基于Eclipse的Hadoop应用开发环境配置(zhuanzai)
我的开发环境:
操作系统centos5.5 一个namenode 两个datanode
Hadoop版本:hadoop-0.20.203.0
Eclipse版本:eclipse-java-helios-SR2-linux-gtk.tar.gz(使用3.7的版本总是崩溃,让人郁闷)
第一步:先启动hadoop守护进程
具体参看:http://www.cnblogs.com/flyoung2008/archive/2011/11/29/2268302.html
第二步:在eclipse上安装hadoop插件
1.复制 hadoop安装目录/contrib/eclipse-plugin/hadoop-0.20.203.0-eclipse-plugin.jar 到 eclipse安装目录/plugins/ 下。
2.重启eclipse,配置hadoop installation directory。
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation directory。配置完成后退出。

3.配置Map/Reduce Locations。
在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中新建一个Hadoop Location。在这个View中,右键-->New Hadoop Location。在弹出的对话框中你需要配置Location name,如Hadoop,还有Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。如:
Map/Reduce Master
192.168.1.101 9001
DFS Master
192.168.1.101 9000

配置完后退出。点击DFS Locations-->Hadoop如果能显示文件夹(2)说明配置正确,如果显示"拒绝连接",请检查你的配置。

第三步:新建项目。
File-->New-->Other-->Map/Reduce Project
项目名可以随便取,如WordCount。
复制 hadoop安装目录/src/example/org/apache/hadoop/example/WordCount.java到刚才新建的项目下面。
第四步:上传模拟数据文件夹。
为了运行程序,我们需要一个输入的文件夹,和输出的文件夹。
在本地新建word.txt
java c++ python c java c++ javascript helloworld hadoop mapreduce java hadoop hbase
通过hadoop的命令在HDFS上创建/tmp/workcount目录,命令如下:bin/hadoop fs -mkdir /tmp/wordcount
通过copyFromLocal命令把本地的word.txt复制到HDFS上,命令如下:bin/hadoop fs -copyFromLocal /home/grid/word.txt /tmp/wordcount/word.txt
第五步:运行项目
1.在新建的项目Hadoop,点击WordCount.java,右键-->Run As-->Run Configurations
2.在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
3.配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如:
hdfs://centos1:9000/tmp/wordcount/word.txt hdfs://centos1:9000/tmp/wordcount/out
4、如果运行时报java.lang.OutOfMemoryError: Java heap space 配置VM arguments(在Program arguments下)
-Xms512m -Xmx1024m -XX:MaxPermSize=256m

5.点击Run,运行程序。
点击Run,运行程序,过段时间将运行完成,等运行结束后,查看运行结果,使用命令: bin/hadoop fs -ls /tmp/wordcount/out查看例子的输出结果,发现有两个文件夹和一个文件,使用命令查看part-r-00000文件, bin/hadoop fs -cat /tmp/wordcount/out/part-r-00000可以查看运行结果。

c 1 c++ 2 hadoop 2 hbase 1 helloworld 1 java 3 javascript 1 mapreduce 1 python 1
hadoop上执行mahout的bayes分类算法
这两天做了一个hadoop上跑的分类算法——贝叶斯分类。下面介绍一下实验的运行过程。。
1,获取数据集:http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz(做分类实验通常用的数据集)
2,解压数据:我的位置:/home/XXXXXX/hadoop/mahout/mahout-distribution-0.6/examples/bin/work
3,预处理训练数据集并需要把txtfile转换成sequenceFile(mahout处理的文件必须是sequenceFile格式的)。命令:mahout org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups -p /home/XXXXXX/hadoop/mahout/mahout-distribution-0.6/examples/bin/work/20news-bydate-train -o /home/XXXXXX/hadoop/mahout/mahout-distribution-0.6/examples/bin/work/bayes-train-input -a org.apache.mahout.vectorizer.DefaultAnalyzer -c UTF-8
4,将work下的bayes-train-input放到hadoop的分布式文件系统上的 20news-input。命令:hadoop dfs -put /home/XXXXXX/hadoop/mahout/mahout-distribution-0.6/examples/bin/work/bayes-train-input 20news-input
5,用处理好的训练数据集进行训练得出分类模型即中间结果。命令:mahout trainclassifier -i 20news-input -o newsmodel -type bayes -ng 3 -source hdfs
查看分类模型的内容:命令:hadoop fs -lsr /user/hadoop/newsmodel;还可以导出到本地的txt格式查看:命令:mahout seqdumper -s /user/XXXXXX/newsmodel/trainer-tfIdf//trainer-tfIdf/part-00000 -o /home/XXXXXX/hadoop/out/part-1
插入一张图片,不然显得太单调了:
6,用模型测试。命令:mahout testclassifier -m newsmodel -d 20news-input -type bayes -ng 3 -source hdfs -method mapreduce
用模型测试时还有点小错误,先这样写上,等测试成功了然后再纠正此处的错误。。见谅
hadoop上执行mahout的kmeans算法
Mahout 是一套具有可扩充能力的机器学习类库。它提供机器学习框架的同时,还实现了一些可扩展的机器学习领域经典算法的实现,可以帮助开发人员更加方便快捷地创建智能应用程序。通过和 Apache Hadoop 分布式框架相结合,Mahout 可以有效地使用分布式系统来实现高性能计算。(类官方的解释)
做这个实验我感觉最重要的就是hadoop与mahout的版本问题。我先后进行了三大次的尝试,总算是跑成功了,这里写出来,提供给想做这个实验的一些小经验吧。
先写出用的两条重要的命令吧:
执行聚类:mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
分析聚类的结果:$MAHOUT_HOME/bin/mahout clusterdump --seqFileDir /user/xxxxxx/output/clusters-10-final --pointsDir /user/kerry/output/clusteredPoints --output $MAHOUT_HOME/examples/output/clusteranalyze.txt 注:xxxxxx代表用户名
第一次:我用的是hadoop-0.20.2和mahout0.4-mahout0.7,jdk1.6
mahout能在本地运行,但是不能在hadoop运行。
第二次:hadoop-1.0.3 和mahout0.6 jdk0.6
mahout能在hadoop上执行聚类,但是在执行的中间会报错:org.apache.mahout.math.CardinalityException: Required cardinality 23 but got 60
第三次:hadoop-1.1.2和mahout0.6 jdk0.7(由于一次失误操作,我把本次实验需要的全部软件和数据都删除了,所以就都换新的软件进行了尝试,本来没想到会跟hadoop的版本有这么大的关系的,在此提醒:一定要做好备份)
mahout能在hadoop上执行聚类,并且能够对聚类结果进行分析,即实验完成。
实验过程:
1、装hadoop和mahout(也就是配置环境变量)
转一篇很全的debian安装和各种设置文章
一.准备安装Debian系统
1.Debian简介
Debian是由GPL和其他自由软件许可协议授权的自由软件组成的操作系统,由Debian计划(Debian Project)组织维护。Debian计划没有任何的营利组织支持,它的开发团队完全由来自世界各地的志愿者组成,官方开发者的总数超过1000名,非官方开发者为数更多。
Debian计划组织跟其他自由操作系统(如Ubuntu、openSUSE、Fedora、Mandriva、OpenSolaris等)的开发组织不同。上述这些自由操作系统的开发组织通常背后由公司或机构支持。而Debian计划组织则完全是一个独立的、分散的开发者组织,纯粹由志愿者组成,背后没有任何公司或机构支持。
Debian以其坚守Unix和自由软件的精神,以及其给予用户的众多选择而闻名。现时Debian包括了超过25,000个软件包并支持12个计算机系统结构。
需要指出的是,Debian并不是一种Linux发行版。Debian是一个大的系统组织框架,在这个框架下有多种不同操作系统核心的分支计划,如采用Linux核心的Debian GNU/Linux系统、采用GNU Hurd核心的Debian GNU/Hurd系统、采用FreeBSD核心的Debian GNU/kFreeBSD系统,以及采用NetBSD核心的Debian GNU/NetBSD系统。甚至还有应用Debian的系统架构和工具,采用OpenSolaris核心构建而成的Nexenta OS系统。在这些Debian系统中,以采用Linux核心的Debian GNU/Linux最为著名。众多的Linux发行版,例如Ubuntu、Knoppix和Linspire及Xandros等,都建基于Debian GNU/Linux。
介绍Debian版本
Debian主要分三个版本:稳定版本(stable)、测试版本(testing)、不稳定版本(unstable)。
这3个发布版同时存在,可以被用户任意选用,用户如果追求稳定、少升级,可以使用stable,这里只有一些安全更新,而不会有其他升级。而对于桌面用户,testing是比较好的选择,因为这里会经常有软件更新,满足用户更多需求。对于一些比较有经验的玩家,unstable是比较好的选择,一方面及时使用新软件,另一方面,偶尔也会遇到一些问题,正好参与测试、修补、回报开源社区。
Debian的正式发音
Debian正式的发音是'deb ee n'. Deb中的e是短音,重音在第一音节。注音为debeen /'dɛbiːjən/ (美式),发音对应汉语里的两个字可以是玳斌,待宾。
Debian软件包管理
当然,人们真正需要的是应用软件,也就是帮助他们完成他们想完成的工作的程序:从编辑文档,进行商业交易,玩游戏,到写更多其他的软件。Debian带来了超过25,000个软件包(为了方便用户使用,这些软件包都已经被编译包装为一种方便的格式,开发人员把它叫做deb包)──这些全部都是自由软件 。
而Debian上的软件管理系统为APT,亦有图形界面的synaptic和aptitude可供使用。
官方网站与文档
官方主页 http://www.debian.org
官方安装说明 http://www.debian.org/releases/stable/installmanual
官方参考手册 http://www.debian.org/doc/manuals/reference
官方Wiki http://wiki.debian.org/
香港Wiki http://wiki.debian.org.hk
2.获得Debian发行版
官方下载:
http://www.debian.org/distrib/
网络安装镜像:(引导安装)
http://cdimage.debian.org/debian-cd/6.0.0/i386/iso-cd/debian-6.0.0-i386-netinst.iso (i386)
http://cdimage.debian.org/debian-cd/6.0.0/amd64/iso-cd/debian-6.0.0-amd64-netinst.iso (amd64)
可以用来完成安装的第一张CD:(基本软件)
http://cdimage.debian.org/debian-cd/6.0.0/i386/bt-cd/debian-6.0.0-i386-CD-1.iso.torrent (i386)
http://cdimage.debian.org/debian-cd/6.0.0/amd64/bt-cd/debian-6.0.0-amd64-CD-1.iso.torrent (amd64)
离线用户可以下载第一张DVD:(完整)
http://cdimage.debian.org/debian-cd/6.0.0/i386/bt-dvd/debian-6.0.0-i386-DVD-1.iso.torrent (i386)
http://cdimage.debian.org/debian-cd/6.0.0/amd64/bt-dvd/debian-6.0.0-amd64-DVD-1.iso.torrent (amd64)
3.硬盘分区方案
在计算机上安装Linux系统,对硬盘进行分区是一个非常重要的步骤,下面介绍几个分区方案。
(1)方案1(初学者)
/ :建议大小在5GB以上。
/home:存放普通用户的数据,是普通用户的宿主目录,建议大小为剩下的空间。
swap:即交换分区,建议大小是物理内存的1~2倍。
(2)方案2(开发者)
/boot:用来存放与Linux系统启动有关的程序,比如启动引导装载程序等,建议大小为100MB以上。
/ :Linux系统的根目录,所有的目录都挂在这个目录下面,建议大小为5GB以上。
/home:存放普通用户的数据,是普通用户的宿主目录,建议大小为剩下的空间。
/usr :用来存放Linux系统中的应用程序,其相关数据较多,建议大于3GB以上。
swap:实现虚拟内存,建议大小是物理内存的1~2倍。
(3)方案3(服务器)
/boot:用来存放与Linux系统启动有关的程序,比如启动引导装载程序等,建议大小为100MB以上。
/usr :用来存放Linux系统中的应用程序,其相关数据较多,建议大于3GB以上。
/var :用来存放Linux系统中经常变化的数据以及日志文件,建议大于1GB以上。
/home:存放普通用户的数据,是普通用户的宿主目录,建议大小为剩下的空间。
/ :Linux系统的根目录,所有的目录都挂在这个目录下面,建议大小为5GB以上。
/tmp:将临时盘在独立的分区,可避免在文件系统被塞满时影响到系统的稳定性。建议大小为500MB以上。
swap:实现虚拟内存,建议大小是物理内存的1~2倍。
二.光盘安装Debian
首先要设置计算机的BIOS启动顺序为光驱启动,保存设置后将安装光盘放入光驱,重新启动计算机。
1.引导系统并开始安装
计算机启动以后会出现如下图所示的界面。

Install 字符界面安装
Graphical install 图形界面安装
Advanced options 高级选项
Help 帮助
选择“Advanced options - 高级选项”进入界面:

Expert install 专家模式安装
Rescue mode 救援模式
Automated install 自动安装
Graphical expert install 专家图形模式安装
Graphical rescue mode 救援图形模式
Graphical automated install 图形自动安装
Alternative desktop environments 选择环境桌面(默认是GNOME)
正如这个界面所示,现在你的主要选项有6个,分别对应是否打开专家模式和是否使用图形界面,建议你使用专家图形模式(Graphical expert install ),专家模式所增加的主要是可选的内容,而不是难度,使用这个模式,即可你不能从中得到什么好处,也至少可以对Debian增加一些了解;而图形界面,可以得到更加直观的操作模式,只要硬件允许即可。
2.语言与区域设置
选择“Chinese Simplified(简体中文)” ,如下图所示。这个语言设置不仅仅是安装程序将使用的语言,也是用户将来安装好的系统的默认语言,而且用户以后随时可以更改它。

下一步是系统的区域设置,它影响到程序界面内容使用哪些语言,以及很多标点符号的表达方式。选择“中国 – zh_CN.UTF-8 ”作为自己的默认locale。

在首选的local之外,还可以选择几个其他的locale来支持,如下图所示,用户也可以不选,只有一个首选的locale不会影响系统正常工作,默认的英文输出和刚刚选择的UTF-8编码的中文已经足够了,也可以选择其他界面语言以适应多种需求。

3.选择键盘布局
选择键盘类型一般默认会选择“English(美国英语)”,即美式键盘,在此使用默认的选择。

4.探测并挂载光盘
接下来寻找光盘镜像,中间会提示加载驱动模块,如下图所示,以支持更多的硬件,如果不需要可以不加载这些驱动,不过,为了备不时之需,在内存不太拮据的情况下,一般按照默认全部加载。

安装程序会提问是否要加载PCMCIA卡,台式计算机根本就没有这个设备,笔记本电脑中一般这个设备不会影响系统安装,除非使用PCMCIA卡接入网络,否则也没有必要加载。
5.加载完整的安装程序
成功发现光盘镜像之后可以从光盘中加载更多的组件用于安装系统,这其中有些模块是可选的,因为之前选择的是专家模式,这些模块会列出供选择,如下图所示,这些附加的模块会满足特定的安装需求,具体如下。

ppp-modules、ppp-udeb:PPP相关模块允许用户使用PPPoE拨号建立ADSL连接,如果用户访问网络需要经过拨号的过程的话就需要选择PPP驱动和PPP守护程序两个模块。
network-console:允许配置网络之后的安装通过远程的SSH访问来完成;
openssh-client:则允许安装程序SSH访问其他计算机获取必要内容。
ntfs-modules:查看ntfs文件系统。
parted-udeb:磁盘管理工具
6.配置网络
加载安装程序组件之后的任务就是配置网络了。如果使用PPPoE拨号的ADSL,那么需要输入账号和密码。而对于通过局域网访问网络的用户,可以依据网络的配置选择自动获取(DHCP)或手工设置IP地址。

配置网络连接之后,要为自己的计算机选定一个主机名和域名,主机名是计算机的名字,而域名是计算机所在的组织的名字,两者组合起来就是计算机的完整域名。对于家庭用户,可能并没有注册过自己的域名,这个位置可以空着,或自己取一个喜欢的。而主机名就是计算机自己的标识,不可以留空,对于企业网中,主机名常常就是使用者的名字或是服务器的用途,如ftp.debian.org,不过,家庭中我们倒是可以起得随意一些。


7.设置用户和密码
首先会询问用户两个用户名密码相关的问题,如下图所示。一个是关于shadow密码的问题,问题里说得很清楚,为了安全应该启用shadow。第二个问题就是系统要不要屏蔽root用户,而通过开放sudo工具提供超级用户权限。通常,Linux系统的普通用户是无法直接进行修改硬件、修改网络设置等特权操作的,只有root用户才具有这些特权,这会带来一些不便,但如果刻意屏蔽root并通过过于宽松的sudo授权策略来进行一些高优先级管理操作的话,可能会对系统安全起负面作用,因此,建议保留root用户。

接下来的输入再次root密码,用以设定密码,是较常规的操作。

之后设置一个日常使用的普通用户,一般来说用户操作自己的各种生活和工作用的文件都会使用这个账号,而不是拥有特权的root,这会保证用户平常没有权力通过误操作使得系统瘫痪。



8.时间和时区设置
首先,安装程序会询问是否启用NTP对时,下图所示。NTP是一个网络时钟同步协议,它会利用网络上的时钟服务器对计算机进行精确的时钟调整,如果你的网络连接正常,并且可以访问到NTP服务器的话,不妨启用NTP;但是,如果你需要通过代理服务器才能上网,并且局域网内部也没有NTP服务器的话,这项功能就没什么意义,可以选否。

一旦你选择了打开NTP对时功能,安装程序接下来就会让你指定时间服务器的域名,如下图所示。对于一些组织,比如中国教育和科研计算机网(CERNET)内部有多个时间服务器,这里,指定一个离自己最近的服务器即可,否则使用默认的服务器。


9.磁盘分区
如果说安装过程真的存在什么风险的话,接下来是风险就要来了,磁盘分区如果操作不当,可能破坏硬盘上的全部数据,因此,这一操作必须谨慎进行。
选择“手工”,然后单击“继续”按钮,如下图所示。

如果是没有分区过的新硬盘,首先选择要安装Debian的硬盘,然后单击“继续”按钮;创建新的分区表的窗口中选择“是”,单击“继续”按钮;会出现分区表类型种选择“msdos”,单击“继续”按钮。



创建“/”分区
选择要分区的空闲空间,点“继续”按钮。 选择“创建新分区”,单击“继续”;下面一一输入完以后,选择“分区设定结束”后,单击“继续”按钮。
分区的新大小:5GB (单位是GB或MB ;也可以用百分比来输入)
新分区的类型:主分区(也逻辑分区,一块硬盘最多主分区4个)
新分区的位置:开始
用于:Ext3日志文件系统(也可以选择Ext4日志文件系统)
挂载点:/





创建“/home”分区
选择要分区的空闲空间,点“继续”按钮。 选择“创建新分区”,单击“继续”;下面一一输入完以后,选择“分区设定结束”后,单击“继续”按钮。
分区的新大小:2.6GB
新分区的类型:主分区
新分区的位置:开始
用于:Ext3日志文件系统
挂载点:/home

创建“swap”分区
选择要分区的空闲空间,点“继续”按钮。 选择“创建新分区”,单击“继续”;下面一一输入完以后,选择“分区设定结束”后,单击“继续”按钮。
分区的新大小:1GB
新分区的类型:主分区
新分区的位置:开始
用于:swap

至此,分区已全部创建完毕,如果不满意,还可以点击“撤消对分区设置的修改”进行更改。如果确定,就点“选择分区设定结束并将修改写入磁盘”,然后单击“继续”按钮后;出现“将改动写入磁盘吗”,选择“是”,然后单击“继续”按钮。


10.安装基本系统
接下来,安装程序会自动从网络上下载安装基本系统,这个过程会安装系统中最基本的文件处理和用户管理工具以及Debian的软件包管理工具等,之后的系统安装配置过程都会利用这些已经安装好的工具来进行。由于安装程序要从网络上下载软件包,这个过程消耗的时间依赖于网络连接的质量。

安装基本系统中惟一需要人工参与的过程是内核的安装,可以选择期望的内核版本。这里给出了几种不同的架构,如486适用于486及其以后的x86 CPU,而686则只适用于Pentium Pro及其以后的处理器,adm64适用于64位的CPU。另外,如果选择2.6内核而非一个特定的版本号,那么,当Debian软件仓库中的内核升级时,系统也会自动向上升级。


12.配置软件包管理器
基本系统安装完成之后,系统安装就进入了下一个阶段:配置软件包管理并安装更多的软件。
想安装最新软件包,使用网络镜像界面当中选择“是”,然后单击“继续”。

接下来要设置的就是选定一台远程的服务器来提供网络安装所需要的软件包,安装程序首先会询问用户是通过FTP还是HTTP的方式下载软件包,如下图所示,有些Debian软件仓库的镜像只提供一种访问方式,选择哪种要看哪个源访问速度比较快。当位于局域网内需要通过代理服务器来访问外部网站的时候,HTTP往往是更好的选择,因为寻找一个稳定的支持FTP连接的代理服务器要困难得多。

随后,安装程序会列出其内置的安装源列表,如下图所示。每一个国家或地区都可能有多个可用源,下图所示的是中国的源的列表。对于广大中国用户来说,可以选择cn99源,也可以选择我国台湾省的源,速度都不错。


选定源之后,如果需要,还可以指定联网所需的代理服务器。而如果没有代理服务器,这里留空就可以了。


是否使用non-free(非自由软件)和contrib(基于非自由软件的自由软件)。


选择有两个为已发布版本提供更新的服务security和volatile,这个服务是用来抵御外来的攻击。

13.选择并安装软件
接下来就是选择并安装软件包了,和很多发布版类似,提供了依据需求选择安装某一方面或几方面的软件包工具,如下图所示,每个方面都会选择一批相关的软件包,这是Debian开发者们为用户精选过的,适合于不是很熟悉系统或是图省事的用户,你也可以只选择“标准系统”,这样会安装很少的包,图形界面也不包括在内,在以后的使用过程中,随时可以安装更多的软件包,适用于追求最小系统或是网络带宽非常有限的系统。

选择完安装任务并让安装过程继续之后,安装程序就暂时不需要人工参与了,依据要安装的软件包的数量和网络带宽情况,下载安装过程可能会持续几分钟到几个小时,界面如下图所示。

14.安装引导程序
在安装的最后,复制完基本系统后,会安装引导程序。默认安装的是Grub,如下图所示。对于大多数用户,应该把GRUB安装到主引导区(MBR),这位可以引导计算机中已经有的所有操作系统。

15.完成系统安装
出现设置系统时钟UTC ,它与“夏令时”有关,我们不需要选择这个选项,否则会造成时区混乱,导致系统显示的时间与本地时间不同。所以 ,选择“否”,单击“继续”后;出现安装完成界面, 单击“继续”。


16.登录界面
重启后出现登录界面,如下图所示。


三.安装后系统基本配置
1.网络配置
配置网卡
修改 /etc/network/interfaces 添加如下
# #号后面是备注,不要添加哦!
auto eth0 #开机自动激活
iface eth0 inte static #静态IP
address 192.168.0.56 #本机IP
netmask 255.255.255.0 #子网掩码
gateway 192.168.0.254 #路由网关
#因为我是通过路由上网的,所以配置为静态IP和网关
如果是用DHCP自动获取,请在配置文件里添加如下:
iface eth0 inet dhcp
设置DNS
echo "nameserver 202.96.128.86" >> /etc/resolv.conf
#请设置为你当地的DNS
到这里配置好以后,重启一下网卡。
/etc/init.d/network restart
2.配置软件源
先备份原来的源列表文件
cp -v /etc/apt/sources.list{,.backup}
修改 /etc/apt/sources.list 先把里边的内容清空,添加如下:
deb http://mirrors.163.com/debian squeeze main non-free contrib
deb http://mirrors.163.com/debian squeeze-proposed-updates main contrib non-free
deb http://mirrors.163.com/debian-security squeeze/updates main contrib non-free
deb-src http://mirrors.163.com/debian squeeze main non-free contrib
deb-src http://mirrors.163.com/debian squeeze-proposed-updates main contrib non-free
deb-src http://mirrors.163.com/debian-security squeeze/updates main contrib non-free
deb http://http.us.debian.org/debian squeeze main contrib non-free
deb http://non-us.debian.org/debian-non-US squeeze/non-US main contrib non-free
deb http://security.debian.org squeeze/updates main contrib non-free
# 也可以直接到163去下载配置文件:http://mirrors.163.com/.help/debian.html
#下载相应版本的sources.list, 覆盖/etc/apt/sources.list即可(操作前请做好相应备份) 本
文以 squeeze 为例
更新软件源列表
apt-get update
更新系统
apt-get upgrade
3.设置本地化 Locale
如果我们在安装 Debian 系统时,语言选择了英语呢?进入系统后看到全是英文,是不是有点郁
闷。那么我们怎样设置成简体中文呢?
#如果你安装系统时选择的就是简体中文,可以跳过这段,只安装中文字体就行了。当然你也可
以修改成其他的语言。
打开终端,执行命令:
dpkg-reconfigure locales
把 带 zh_CN 字样的全部选上,然后选择 OK 确定,在弹出的对话框中,选择系统的 locale ,选择zh_CN.UTF-8。
安装时选择的是英语,会缺少中文字体,用以下命令安装字体:
apt-get install xfonts-intl-chinese wqy*
下次重起机器,在GNOME登录介面下方的Language,登录语言选择:汉语(中国)
4.设置字体
对着桌面猛击右键 ===> 更改桌面背景 ===> 字体
# 选择自己喜欢的字体,比如:文泉驿点阵正黑或文泉驿微米黑
5.输入法
选择喜欢的输入法,比如: ibus scim
# 注:fcitx 输入法在debian unstable 软件源里才有,如果需要的话,只能自行下载安装了。
或者添加 Debian unstable 的软件源。
apt-get install ibus-pinyin ibus-table-wubi #安装IBUS五笔和拼音
设置输入法
系统 ===> 首选项 ===> IBus 设置
#设置快捷键和添加输入法到列表。
6.浏览器
Iceweasel浏览器简体中文组件 # Iceweasel是Debian中Mozilla Firefox浏览器的一个再发布版
#英语很菜,所以浏览器菜单也要是中文的
apt-get install iceweasel-l10n-zh-cn
运行浏览器,然后点击
浏览器菜单 ===> 编辑 ===> 首选项 ===> 内容
# 设置浏览器字体
谷歌开源浏览器Chromium
# 不喜欢用这个的,也可以安装 Chrome 浏览器
apt-get install chromium-browser chromium-browser-l10n
Flash插件
执行命令:
apt-get install flashplugin-nonfree #嫌手动安装官方Flash插件麻烦的,直接安装这个吧
手动安装官方Flash插件
# 注意如果你已经用上面的命令安装了flashplugin-nonfree,最好先卸载掉。
# 可能是为了避免冲突吧,不然浏览器不知道用哪个插件,我不清楚原因。
源里的flash插件和官方的正式版的flash插件,在我这里播放在线视频时,全屏会卡。我安装的
是测试版的flash插件
先下载两个软件包,不然装好了Flash插件也用不了。装源里的 flashplugin-nonfree 会自动安
装这两个文件。
apt-get install ca-certificates libcurl3-gnutls
到下面网址下载 Flash Player 的压缩包
http://labs.adobe.com/downloads/flashplayer10.html
Download plug-in for 32-bit Linux (TAR.GZ, 4.7 MB) ← 下载这个
然后解压下载下来的压缩文件,解压出来
libflashplayer.so
切换到普通用户创建存放 Flash 插件的目录
mkdir -pv ~/.mozilla/plugins
进入存放 libflashplayer.so 的目录
cp -v libflashplayer.so ~/.mozilla/plugins
Chromium安装Flash插件
su
cp -v libflashplayer.so /usr/lib/chromium-browser/plugins
7.影音播放器
#Mplayer和播放前端SMplayer
apt-get install mplayer smplayer
8.设置QT程序字体
# 在Debian GNOME桌面中QT程序的字体不清析,所以要设置一下
先备份 /etc/fonts/conf.d/49-sansserif.conf
cp -v /etc/fonts/conf.d/49-sansserif.conf{,.backup}
修改 /etc/fonts/conf.d/49-sansserif.conf
把文件倒数第4行中:
sans-serif
↓↓
文泉驿微米黑
# 把sans-serif替换成文泉驿微米黑,前提你得先安装文泉驿字库
9.PDF阅读器
Foxit # 如果觉得系统自带的不好用,就下载这个吧
http://www.foxitsoftware.com/downloads/index.php
#找到 Foxit Reader 1.1 Build 20090810 for Desktop Linux(bz2),下载后解压运行目录下的
foxit就可以用。
10.CHM阅读器
如果有Windows下的CHM文档资料要看,那么就安装chmsee吧
apt-get install chmsee
11.星际译王
# 星际译王是 GNOME 中的国际化的词典软件
# 本人英文单词不会几个的,所以是必配的词典软件
apt-get install stardict
#词典下载,下载地址如下,下载tarball包,解压后,复制到 /usr/share/stardict/dict/ 目
录下,
#最好在这个目录下新建文件夹来分类存放词典。
http://stardict.sourceforge.net/Dictionaries_zh_CN.php
12.截图工具shutter
#默认情况下,Debian没有安装gnome-screenshot,可以下载功能更强大的shutter
apt-get install shutter
apt-get install libgoo-canvas-perl # 编辑功能插件
13.解压缩软件
apt-get install unrar
apt-get install unzip
apt-get install p7zip-full
14.安装基本编译环境
# 有时可能自己想编译软件
apt-get install gcc
apt-get install linux-headers-`uname -r`
apt-get install make
apt-get install automake
15.虚拟机VirtualBox-OSE
# 使用 Linux 或多或少都要用虚拟机吧,如果不喜欢OSE版,可以到官方去下载。
apt-get install virtualbox-ose
VirtualBox 官方主页:
http://www.virtualbox.org/
16.FTP上传下载工具
# gFTP是X Window下的一个用Gtk开发的多线程FTP客户端工具
apt-get install gftp
17.LINUX下的“电驴”
# aMule 是基于eMule的“全平台”P2P客户端
apt-get install amule
18.BT下载工具
Transmission是一种BitTorrent客户端
apt-get install transmission
yum使用笔记
1、yum makecache:将服务器上的软件包,现在本地缓存,以提高搜索安装软件的速度。
yum install software_name 安装软件包
yum remove software_name 删除软件包
yum search sofware_name 查找软件包
yum update 更新系统
2、yum 中有的 mirror 速度是非常慢的,如果 yum选择了这个 mirror,这个时候 yum 就会非常慢,
Virtual.box创建虚拟机及其文件共享
又好长时间没写博客了,今天补一篇吧。
由于我正在搞Redis数据库,这个需要在linux环境下,所以今天在虚拟机上装了台Mint(基于Ubuntu的发行版)。这个系统是我以前给学生讲实验课时已经装好的,所以直接加载进去就能用。
关于加载一个现成的linux系统,我在这只写一步:
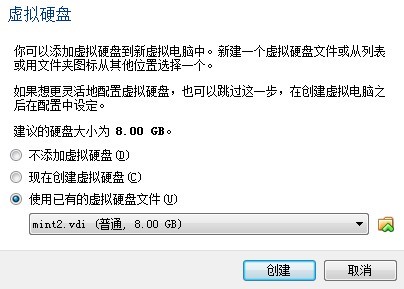
这一步选择已有的vdi即可。
接下来说说设置共享:
设置——>共享文件夹——>选择共享的文件——>选择自动挂载、固定分配(或临时分配)——>确定即可。
然后再linux系统中输入命令:sudo mount -t vboxsf Share ./Share(第一个share是window种的share,第二个share是在linux中创建的文件)
最后ls看一下,共享的文件share,在里面创建文件来验证是否已经设置好。
k近邻法与kd树
这是转过来的文章。。很好的
在使用k近邻法进行分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决的方式进行预测。由于k近邻模型的特征空间一般是n维实数向量,所以距离的计算通常采用的是欧式距离。关键的是k值的选取,如果k值太小就意味着整体模型变得复杂,容易发生过拟合,即如果邻近的实例点恰巧是噪声,预测就会出错,极端的情况是k=1,称为最近邻算法,对于待预测点x,与x最近的点决定了x的类别。k值得增大意味着整体的模型变得简单,极端的情况是k=N,那么无论输入实例是什么,都简单地预测它属于训练集中最多的类,这样的模型过于简单。经验是,k值一般去一个比较小的值,通常采取交叉验证的方法来选取最优的k值。
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索,这点在特征空间的维数大以及训练数据容量大时尤其重要。k近邻法的最简单实现是线性扫描,这时要计算输入实例与每一个训练实例的距离,当训练集很大时,计算非常耗时,这种方法是不可行的。为了提高k近邻搜索的效率,可以考虑使用特殊的结构存储训练数据,以减少计算距离的次数。具体方法有很多,这里介绍kd树方法。
1.实例
先以一个简单直观的实例来介绍k-d树算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内(如图2中黑点所示)。k-d树算法就是要确定图2中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)。下面就要通过一步步展示k-d树是如何确定这些分割线的。

k-d树算法可以分为两大部分,一部分是有关k-d树本身这种数据结构建立的算法,另一部分是在建立的k-d树上如何进行最邻近查找的算法。
2.构造kd树
kd树是一种对k维空间中的实例点进行存储以便对其进行快速搜索的树形数据结构。kd树是二叉树,表示对k维空间的一个划分。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间进行切分,构成一系列的k维超矩形区域。kd树的每一个节点对应于一个k维超矩形区域。k-d树是一个二叉树,每个节点表示一个空间范围。下表给出的是k-d树每个节点中主要包含的数据结构。

从上面对k-d树节点的数据类型的描述可以看出构建k-d树是一个逐级展开的递归过程。下面给出的是构建k-d树的伪码。
- 算法:构建k-d树(createKDTree)
- 输入:数据点集Data-set和其所在的空间Range
- 输出:Kd,类型为k-d tree
- 1.If Data-set为空,则返回空的k-d tree
- 2.调用节点生成程序:
- (1)确定split域:对于所有描述子数据(特征矢量),统计它们在每个维上的数据方差。假设每条数据记录为64维,可计算64个方差。挑选出最大值,对应的维就是split域的值。数据方差大表明沿该坐标轴方向上的数据分散得比较开,在这个方向上进行数据分割有较好的分辨率;
- (2)确定Node-data域:数据点集Data-set按其第split域的值排序。位于正中间的那个数据点被选为Node-data。此时新的Data-set' = Data-set \ Node-data(除去其中Node-data这一点)。
- 3.dataleft = {d属于Data-set' && d[split] ≤ Node-data[split]}
- Left_Range = {Range && dataleft}
- dataright = {d属于Data-set' && d[split] > Node-data[split]}
- Right_Range = {Range && dataright}
- 4.left = 由(dataleft,Left_Range)建立的k-d tree,即递归调用createKDTree(dataleft,Left_Range)。并设置left的parent域为Kd;
- right = 由(dataright,Right_Range)建立的k-d tree,即调用createKDTree(dataleft,Left_Range)。并设置right的parent域为Kd。
以上述举的实例来看,过程如下:
由于此例简单,数据维度只有2维,所以可以简单地给x,y两个方向轴编号为0,1,也即split={0,1}。
(1)确定split域的首先该取的值。分别计算x,y方向上数据的方差得知x方向上的方差最大,所以split域值首先取0,也就是x轴方向;
(2)确定Node-data的域值。根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以Node-data = (7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于split = 0(x轴)的直线x = 7;
(3)确定左子空间和右子空间。分割超平面x = 7将整个空间分为两部分,如下图所示。x <= 7的部分为左子空间,包含3个节点{(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点{(9,6),(8,1)}。

如算法所述,k-d树的构建是一个递归的过程。然后对左子空间和右子空间内的数据重复根节点的过程就可以得到下一级子节点(5,4)和(9,6)(也就是左右子空间的'根'节点),同时将空间和数据集进一步细分。如此反复直到空间中只包含一个数据点,如下图所示。最后生成的k-d树如下图所示。

3.搜索kd树
在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。这里先以一个简单的实例来描述最邻近查找的基本思路。
星号表示要查询的点(2.1,3.1)。通过二叉搜索,顺着搜索路径很快就能找到最邻近的近似点,也就是叶子节点(2,3)。而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶子节点的圆域内。为了找到真正的最近邻,还需要进行'回溯'操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。此例中先从(7,2)点开始进行二叉查找,然后到达(5,4),最后到达(2,3),此时搜索路径中的节点为小于(7,2)和(5,4),大于(2,3),首先以(2,3)作为当前最近邻点,计算其到查询点(2.1,3.1)的距离为0.1414,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点。以(2.1,3.1)为圆心,以0.1414为半径画圆,如下图所示。发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中去搜索。

再回溯到(7,2),以(2.1,3.1)为圆心,以0.1414为半径的圆更不会与x = 7超平面交割,因此不用进入(7,2)右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2,3),最近距离为0.1414。
一个复杂点了例子如查找点为(2,4.5)。同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,取(4,7)为当前最近邻点,计算其与目标查找点的距离为3.202。然后回溯到(5,4),计算其与查找点之间的距离为3.041。以(2,4.5)为圆心,以3.041为半径作圆,如下图左所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找。此时需将(2,3)节点加入搜索路径中得<(7,2),(2,3)>。回溯至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5。回溯至(7,2),以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图右所示。至此,搜索路径回溯完。返回最近邻点(2,3),最近距离1.5。

k-d树查询算法的伪代码如下所示。
- 算法:k-d树最邻近查找
- 输入:Kd, //k-d tree类型
- target //查询数据点
- 输出:nearest, //最邻近数据点
- dist //最邻近数据点和查询点间的距离
- 1. If Kd为NULL,则设dist为infinite并返回
- 2. //进行二叉查找,生成搜索路径
- Kd_point = &Kd; //Kd-point中保存k-d tree根节点地址
- nearest = Kd_point -> Node-data; //初始化最近邻点
- while(Kd_point)
- push(Kd_point)到search_path中; //search_path是一个堆栈结构,存储着搜索路径节点指针
- /*** If Dist(nearest,target) > Dist(Kd_point -> Node-data,target)
- nearest = Kd_point -> Node-data; //更新最近邻点
- Max_dist = Dist(Kd_point,target); //更新最近邻点与查询点间的距离 ***/
- s = Kd_point -> split; //确定待分割的方向
- If target[s] <= Kd_point -> Node-data[s] //进行二叉查找
- Kd_point = Kd_point -> left;
- else
- Kd_point = Kd_point ->right;
- nearest = search_path中最后一个叶子节点; //注意:二叉搜索时不比计算选择搜索路径中的最邻近点,这部分已被注释
- Max_dist = Dist(nearest,target); //直接取最后叶子节点作为回溯前的初始最近邻点
- 3. //回溯查找
- while(search_path != NULL)
- back_point = 从search_path取出一个节点指针; //从search_path堆栈弹栈
- s = back_point -> split; //确定分割方向
- If Dist(target[s],back_point -> Node-data[s]) < Max_dist //判断还需进入的子空间
- If target[s] <= back_point -> Node-data[s]
- Kd_point = back_point -> right; //如果target位于左子空间,就应进入右子空间
- else
- Kd_point = back_point -> left; //如果target位于右子空间,就应进入左子空间
- 将Kd_point压入search_path堆栈;
- If Dist(nearest,target) > Dist(Kd_Point -> Node-data,target)
- nearest = Kd_point -> Node-data; //更新最近邻点
- Min_dist = Dist(Kd_point -> Node-data,target); //更新最近邻点与查询点间的距离
当维数较大时,直接利用k-d树快速检索的性能急剧下降。假设数据集的维数为D,一般来说要求数据的规模N满足条件:N远大于2的D次方,才能达到高效的搜索。
归并排序(c++实现)
今天用c++实现了归并排序,算法的思路说起来挺简单的,但是今天去实现的时候发现问题挺多的,首先就是递归这种思路本身就不好理解,不过还好毕竟是一个小算法,想一想就搞定了。。
代码如下:
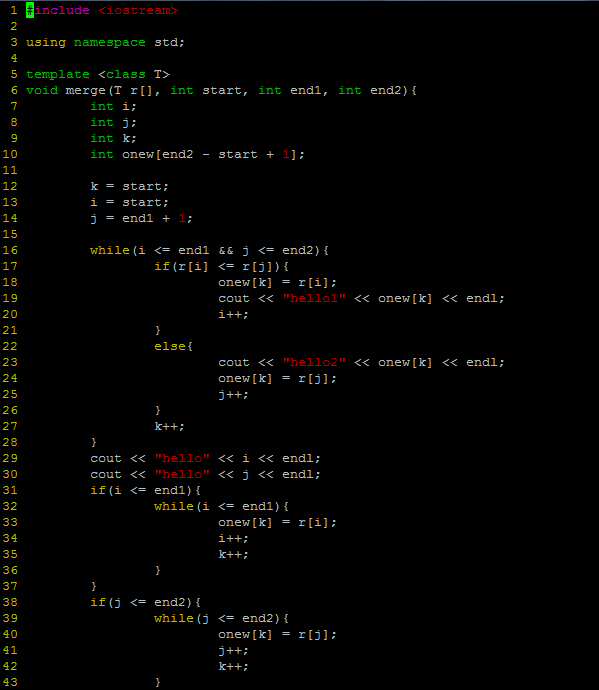
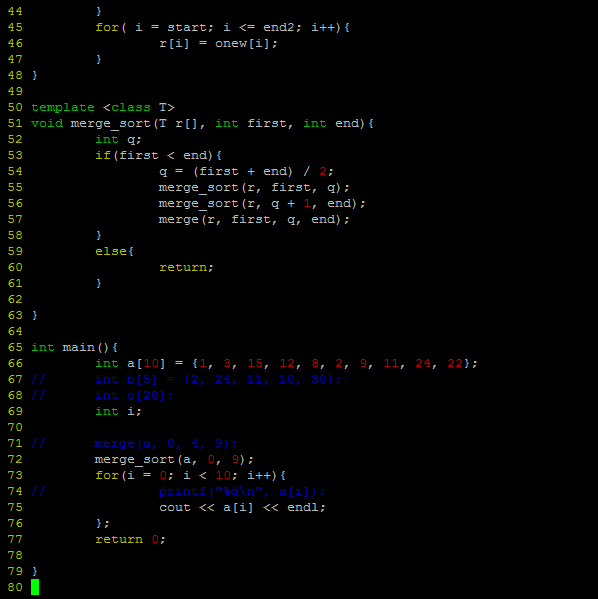
由于时间关系,在此就不多解释了,如果谁感兴趣的话或者我写的哪点有问题的话,可以交流一下。。