至从C语言开始enum类型就被作为用户自定义分类有限集合常量的方法被引入到了语言当中,而且一度成为C++中定义编译期常量的唯一方法(后来在类中引入了静态整型常量)。根据上面对enum类型的描述,到底enum所定义出来的类型是一个什么样的类型呢?作为一个用户自定义的类型其所占用的内存空间是多少呢?使用enum类型是否真的能够起到有限集合常量的边界约束呢?大家可能都知道enum类型和int类型具有隐示(自动)转换的规则,那么是否真的在任何地方都可以使用enum类型的变量来代替int类型的变量呢?下面会逐一回答这些问题。
1. 到底enum所定义出来的类型是一个什么样的类型呢?
在C++中大家都知道仅仅有两种大的类型分类:POD类型和类类型(不清楚的可以参见我的其他文章)。enum所定义的类型其实属于POD类型,也就是说它会参与到POD类型的隐示转换规则当中去,所以才会出现enum类型与int类型之间的隐示转换现象。那么也就是说enum所定义的类型不具备名字空间限定能力(因为不属于类类型),其所定义的常量子具备和enum类型所在名字空间相同的可见性,由于自身没有名字限定能力,所以会出现名字冲突现象。如:
struct CEType
{
enum EType1 { e1, e2 };
enum EType2 { e1, e2 };
};
上面的例子会出现e1、e2名字冲突编译时错误,原因就在于枚举子(e1、e2)是CEType名字空间中的名字,同样在引用该CEType中的枚举子时必须采用CEType::e1这样的方式进行,而不是CEType::EType1::e1来进行引用。
2. 作为一个用户自定义的类型其所占用的内存空间是多少呢?
该问题就是sizeof( EType1 )等于多少的问题,是不是每一个用户自定义的枚举类型都具有相同的尺寸呢?在大多数的32位编译器下(如:VC++、gcc等)一个枚举类型的尺寸其实就是一个sizeof( int )的大小,难道枚举类型的尺寸真的就应该是int类型的尺寸吗?其实不是这样的,在C++标准文档(ISO14882)中并没有这样来定义,
标准中是这样说明的:“枚举类型的尺寸是以能够容纳最大枚举子的值的整数的尺寸”,同时标准中也说名了:“枚举类型中的枚举子的值必须要能够用一个int类型表述”,也就是说,枚举类型的尺寸不能够超过int类型的尺寸,但是是不是必须和int类型具有相同的尺寸呢?上面的标准已经说得很清楚了,只要能够容纳最大的枚举子的值的整数就可以了,那么就是说可以是char、short和int。例如:
enum EType1 { e1 = CHAR_MAX };
enum EType2 { e2 = SHRT_MAX };
enum EType3 { e3 = INT_MAX };
上面的三个枚举类型分别可以用char、short、int的内存空间进行表示,也就是:
sizeof( EType1 ) == sizeof( char );
sizeof( EType2 ) == sizeof( short );
sizeof( EType3 ) == sizeof( int );
那为什么在32位的编译器下都会将上面三个枚举类型的尺寸编译成int类型的尺寸呢?主要是从32位数据内存对其方面的要求进行考虑的,在某些计算机硬件环境下具有对齐的强制性要求(如:sun SPARC),有些则是因为采用一个完整的32位字长CPU处理效率非常高的原因(如:IA32)。所以不可以简单的假设枚举类型的尺寸就是int类型的尺寸,说不定会遇到一个编译器为了节约内存而采用上面的处理策略。
3. 使用enum类型是否真的能够起到有限集合常量的边界约束呢?
首先看一下下面这个例子:
enum EType { e1 = 0, e2 };
void func1( EType e )
{
if ( e == e1 )
{
// do something
}
// do something because e != e1 must e == e2
}
void func2( EType e )
{
if ( e == e1 )
{
// do something
}
else if ( e == e2 )
{
// do something
}
}
func1( static_cast<EType>( 2 ) );
func2( static_cast<EType>( -1 ) );
上面的代码应该很清楚的说明了这样一种异常的情况了,在使用一个操出范围的整型值调用func1函数时会导致函数采取不该采取的行为,而第二个函数可能会好一些他仅仅是忽略了超出范围的值。这就说明枚举所定义的类型并不是一个真正强类型的有限常量集合,这样一种条件下和将上述的两个函数参数声明成为整数类型没有任何差异。所以以后要注意标准定义中枚举类型的陷阱。(其实只有类类型才是真正的强类型)
4. 是否真的在任何地方都可以使用enum类型的变量来代替int类型的变量呢?通过上面的讨论,其实枚举类型的变量和整型变量具有了太多的一致性和可互换性,那么是不是在每一个可以使用int类型的地方都可以很好的用枚举类型来替代呢?其实也不是这样的,毕竟枚举类型是一个在编译时可区分的类型,同时第2点的分析枚举类型不一定和int类型具有相同的尺寸,这两个差异就决定了在某些场合是不可以使用枚举类型来代替int类型的。如:
第一种情况:
enum EType { e1 = 0, e2, e3 };
EType val;
std::cin >> val;
第二种情况:
enum EType { e1 = 0, e2, e3 };
EType val;
std::scanf( "%d", &val );
上面的两种情况看是基本上属于同一种类型的问题,其实不然。第一种情况会导致编译时错误,会因为std::cin没有定义对应的枚举类型的重载>>运算符而出错,这就说明枚举类型是一种独立和鉴别的类型;而第二种情况不会有任何编译时问题,但是可能会导致scanf函数栈被破坏而使得程序运行非法,为什么会这样呢?上面已经分析过了枚举类型变量的尺寸不一定和int类型相同,这样一来我们采用%d就是说将枚举类型变量val当作4字节的int变量来看待并进行参数压栈,而在某些编译器下sizeof( val )等于1字节,这样scanf函数就会将val变量地址中的后续的三字节地址也压入栈中,并对其进行赋值,也许val变量后续的三个字节的地址没有特殊含义可以被改写(比如是字节对齐的空地址空间),可能会认为他不会出现错误,其实不然,在scanf函数调用结束后会进行栈清理,这样一来会导致scanf函数清理了过多的地址空间,从而破坏了外围函数的栈指针的指向,从而必然会导致程序运行时错误。
由上面的说明枚举类型有那么多的缺点,那我们怎样才能够有一个类型安全的枚举类型
呢?其实可以采用类类型来模拟枚举类型的有限常量集合的概念,同时得到类型安全的好处,
沙诺 Blog
Happy coding
shanuo
分类
最新评论
最新留言
链接
RSS
功能
Git常用命令
1) 远程仓库相关命令
检出仓库:$ git clone git://github.com/jquery/jquery.git
查看远程仓库:$ git remote -v
添加远程仓库:$ git remote add [name] [url]
删除远程仓库:$ git remote rm [name]
拉取远程仓库:$ git pull [remoteName] [localBranchName]
推送远程仓库:$ git push [remoteName] [localBranchName]
2)分支(branch)操作相关命令
查看本地分支:$ git branch
查看远程分支:$ git branch -r
创建本地分支:$ git branch [name] —-注意新分支创建后不会自动切换为当前分支
切换分支:$ git checkout [name]
创建新分支并立即切换到新分支:$ git checkout -b [name]
删除分支:$ git branch -d [name] —- -d选项只能删除已经参与了合并的分支,对于未有合并的分支是无法删除的。如果想强制删除一个分支,可以使用-D选项
合并分支:$ git merge [name] —-将名称为[name]的分支与当前分支合并
创建远程分支(本地分支push到远程):$ git push origin [name]
删除远程分支:$ git push origin :heads/[name]
3)版本(tag)操作相关命令
查看版本:$ git tag
创建版本:$ git tag [name]
删除版本:$ git tag -d [name]
查看远程版本:$ git tag -r
创建远程版本(本地版本push到远程):$ git push origin [name]
删除远程版本:$ git push origin :refs/tags/[name]
4) 子模块(submodule)相关操作命令
添加子模块:$ git submodule add [url] [path]
初始化子模块:$ git submodule init
更新子模块:$ git submodule update —-每次更新或切换分支后都需要运行一下
删除子模块:$ git rm –cached [path]
5)忽略一些文件、文件夹不提交
在仓库根目录下创建名称为“.gitignore”的文件,写入不需要的文件夹名或文件,每个元素占一行即可,如
target
bin
*.db
归并排序(c++实现)
今天用c++实现了归并排序,算法的思路说起来挺简单的,但是今天去实现的时候发现问题挺多的,首先就是递归这种思路本身就不好理解,不过还好毕竟是一个小算法,想一想就搞定了。。
代码如下:
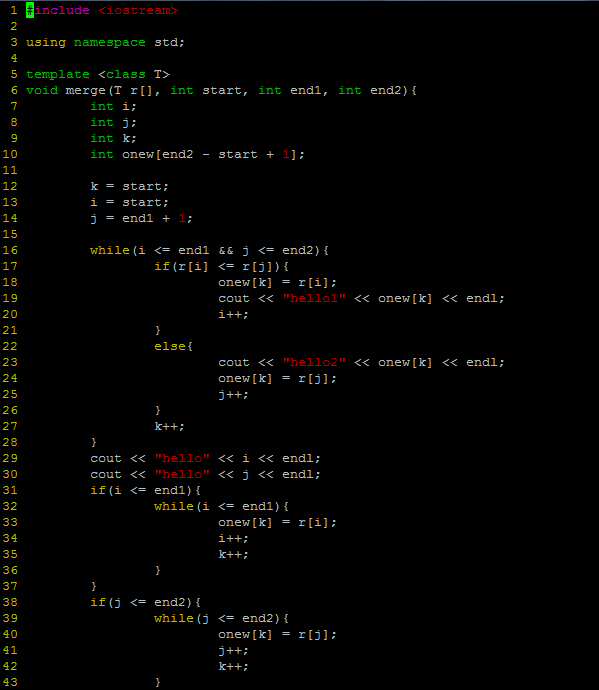
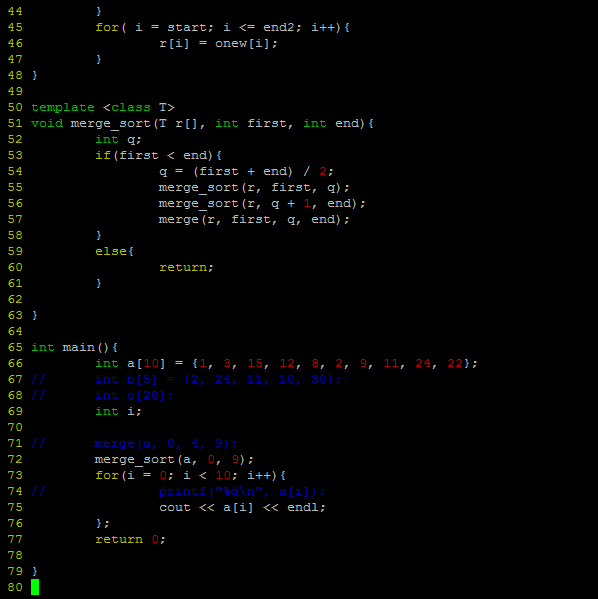
由于时间关系,在此就不多解释了,如果谁感兴趣的话或者我写的哪点有问题的话,可以交流一下。。
选择排序(C实现)
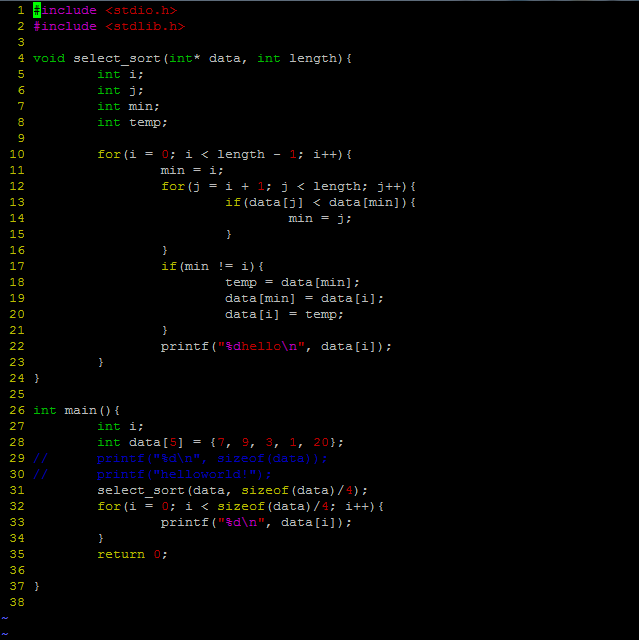
程序很简单,但是有些小细节:
1、sizeof(data):取到的是字节数,还要除以4才能得出元素个数。。
2、设置变量min记录数组下标,而不要频繁的交换。。
各种排序陆续送上。。
enum类型的本质(转)
c中产生随机数的方法
c中产生随机数可以结合srand()和rand()两个函数,这两个函数都是在标准库 stdlib.h 中。
srand()函数可以初始化种子,种子的概念在此简单说一下,产生一个随机数要有一个最开始的值,然后随机数就是根据这个值算出来的,这个原始的值就是种子,所以只要我们的种子不同,产生的随机数就不同。因此我们一般以当前时间作为种子。具体用法如下:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <time.h>
4 int main()
5 {
6 srand((unsigned)time(NULL));
7 printf("Random number in the 0-100 range: %d\n", rand()%101);
8 return 0;
9 }
这样我们就可以产生0-100 的随机数了。