沙诺 Blog
Happy coding
shanuo
分类
最新评论
最新留言
链接
RSS
功能
hadoop运行mahout的贝叶斯
mahout运行bayes(贝叶斯)算法的前提条件:
(1)启动hadoop
hadoop@master:~$ start-all.sh
(2)成功编译mahout源码
hadoop@master:~$ cd $MAHOUT_HOME
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mvn install -Dmaven.test.skip=true
mahout运行bayes(贝叶斯)算法的步骤:
(1)生成input的数据
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mahout org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups -p /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-data/20news-bydate/20news-bydate-train -o /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-result/bayes-train-input -a org.apache.mahout.vectorizer.DefaultAnalyzer -c UTF-8
运行结果:
Running on hadoop, using HADOOP_HOME=/home/hadoop/cloud/hadoop-1.0.4
HADOOP_CONF_DIR=/home/hadoop/cloud/confDir/hadoop/conf
Warning: $HADOOP_HOME is deprecated.
13/08/09 14:07:09 WARN driver.MahoutDriver: No org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups.props found on classpath, will use command-line arguments only
13/08/09 14:07:14 INFO driver.MahoutDriver: Program took 5202 ms
(2)生成test的数据
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mahout org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups -p /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-data/20news-bydate/20news-bydate-test -o /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-result/bayes-test-input -a org.apache.mahout.vectorizer.DefaultAnalyzer -c UTF-8
运行结果:
Running on hadoop, using HADOOP_HOME=/home/hadoop/cloud/hadoop-1.0.4
HADOOP_CONF_DIR=/home/hadoop/cloud/confDir/hadoop/conf
Warning: $HADOOP_HOME is deprecated.
13/08/09 14:13:35 WARN driver.MahoutDriver: No org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups.props found on classpath, will use command-line arguments only
13/08/09 14:13:38 INFO driver.MahoutDriver: Program took 3428 ms
(3)将训练文本集上传到HDFS上
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ hadoop dfs -put /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-result/bayes-train-input/ bayes-train-input
(4)模型训练:依据训练文本集来训练贝叶斯分类器模型
解释一下命令:-i:表示训练集的输入路径,HDFS路径; -o:分类模型输出路径; -type:分类器类型,这里使用bayes,可选cbayes;
-ng:(n-gram)建模的大小,默认为1; -source:数据源的位置,HDFS或HBase
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mahout trainclassifier -i bayes-train-input -o bayes-newsmodel -type bayes -ng 1 -source hdfs
(5)将测试文本集上传到HDFS上
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ hadoop dfs -put /home/hadoop/mahout-0.5-src/mahout-distribution-0.5/my-test-result/bayes-test-input/ bayes-test-input
(6)模型测试:依据训练的贝叶斯分类器模型来进行分类测试
hadoop@master:~/mahout-0.5-src/mahout-distribution-0.5$ mahout testclassifier -m bayes-newsmodel -d bayes-test-input -type bayes -ng 1 -source hdfs -method mapreduce
运行结果(与apache官网里面的一致):
13/08/09 14:56:34 INFO bayes.BayesClassifierDriver: =======================================================
Confusion Matrix
-------------------------------------------------------
a b c d e f g h i j k l m n o p q r s t u <--Classified as
381 0 0 0 0 9 1 0 0 0 1 0 2 0 0 1 0 0 3 0 0 | 398 a = rec.motorcycles
1 284 0 0 0 0 1 0 6 3 11 0 3 66 0 1 6 0 4 9 0 | 395 b = comp.windows.x
2 0 339 2 0 3 5 1 0 0 0 0 1 1 12 1 7 0 2 0 0 | 376 c = talk.politics.mideast
4 0 1 327 0 2 2 0 0 2 1 1 5 0 1 4 12 0 2 0 0 | 364 d = talk.politics.guns
7 0 4 32 27 7 7 2 0 12 0 0 0 6 100 9 7 31 0 0 0 | 251 e = talk.religion.misc
10 0 0 0 0 359 2 2 0 1 3 0 6 1 0 1 0 0 11 0 0 | 396 f = rec.autos
0 0 0 0 0 1 383 9 1 0 0 0 0 0 0 0 0 0 3 0 0 | 397 g = rec.sport.baseball
1 0 0 0 0 0 9 382 0 0 0 0 1 1 1 0 2 0 2 0 0 | 399 h = rec.sport.hockey
2 0 0 0 0 4 3 0 330 4 4 0 12 5 0 0 2 0 12 7 0 | 385 i = comp.sys.mac.hardware
0 3 0 0 0 0 1 0 0 368 0 0 4 10 1 3 2 0 2 0 0 | 394 j = sci.space
0 0 0 0 0 3 1 0 27 2 291 0 25 11 0 0 1 0 13 18 0 | 392 k = comp.sys.ibm.pc.hardware
8 0 1 109 0 6 11 4 1 18 0 98 3 1 11 10 27 1 1 0 0 | 310 l = talk.politics.misc
6 0 1 0 0 4 2 0 5 2 12 0 321 8 0 4 14 0 8 6 0 | 393 m = sci.electronics
0 11 0 0 0 3 6 0 10 7 11 0 13 298 0 2 13 0 7 8 0 | 389 n = comp.graphics
2 0 0 0 0 0 4 1 0 3 1 0 1 3 372 6 0 2 1 2 0 | 398 o = soc.religion.christian
4 0 0 1 0 2 3 3 0 4 2 0 12 7 6 342 1 0 9 0 0 | 396 p = sci.med
0 1 0 1 0 1 4 0 3 0 1 0 4 8 0 2 369 0 1 1 0 | 396 q = sci.crypt
10 0 4 10 1 5 6 2 2 6 2 0 1 2 86 15 14 152 0 1 0 | 319 r = alt.atheism
4 0 0 0 0 9 1 1 8 1 12 0 6 3 0 2 0 0 341 2 0 | 390 s = misc.forsale
8 5 0 0 0 1 6 0 8 5 50 0 2 39 1 0 9 0 3 257 0 | 394 t = comp.os.ms-windows.misc
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 | 0 u = unknown
Default Category: unknown: 20
13/08/09 14:56:34 INFO driver.MahoutDriver: Program took 118128 ms
这一篇是转的,上一篇是自己写的,但是自己写的中间过程不完整,所以又转了一篇。
基于Eclipse的Hadoop应用开发环境配置(zhuanzai)
我的开发环境:
操作系统centos5.5 一个namenode 两个datanode
Hadoop版本:hadoop-0.20.203.0
Eclipse版本:eclipse-java-helios-SR2-linux-gtk.tar.gz(使用3.7的版本总是崩溃,让人郁闷)
第一步:先启动hadoop守护进程
具体参看:http://www.cnblogs.com/flyoung2008/archive/2011/11/29/2268302.html
第二步:在eclipse上安装hadoop插件
1.复制 hadoop安装目录/contrib/eclipse-plugin/hadoop-0.20.203.0-eclipse-plugin.jar 到 eclipse安装目录/plugins/ 下。
2.重启eclipse,配置hadoop installation directory。
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation directory。配置完成后退出。

3.配置Map/Reduce Locations。
在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中新建一个Hadoop Location。在这个View中,右键-->New Hadoop Location。在弹出的对话框中你需要配置Location name,如Hadoop,还有Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。如:
Map/Reduce Master
192.168.1.101 9001
DFS Master
192.168.1.101 9000

配置完后退出。点击DFS Locations-->Hadoop如果能显示文件夹(2)说明配置正确,如果显示"拒绝连接",请检查你的配置。

第三步:新建项目。
File-->New-->Other-->Map/Reduce Project
项目名可以随便取,如WordCount。
复制 hadoop安装目录/src/example/org/apache/hadoop/example/WordCount.java到刚才新建的项目下面。
第四步:上传模拟数据文件夹。
为了运行程序,我们需要一个输入的文件夹,和输出的文件夹。
在本地新建word.txt
java c++ python c java c++ javascript helloworld hadoop mapreduce java hadoop hbase
通过hadoop的命令在HDFS上创建/tmp/workcount目录,命令如下:bin/hadoop fs -mkdir /tmp/wordcount
通过copyFromLocal命令把本地的word.txt复制到HDFS上,命令如下:bin/hadoop fs -copyFromLocal /home/grid/word.txt /tmp/wordcount/word.txt
第五步:运行项目
1.在新建的项目Hadoop,点击WordCount.java,右键-->Run As-->Run Configurations
2.在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
3.配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如:
hdfs://centos1:9000/tmp/wordcount/word.txt hdfs://centos1:9000/tmp/wordcount/out
4、如果运行时报java.lang.OutOfMemoryError: Java heap space 配置VM arguments(在Program arguments下)
-Xms512m -Xmx1024m -XX:MaxPermSize=256m

5.点击Run,运行程序。
点击Run,运行程序,过段时间将运行完成,等运行结束后,查看运行结果,使用命令: bin/hadoop fs -ls /tmp/wordcount/out查看例子的输出结果,发现有两个文件夹和一个文件,使用命令查看part-r-00000文件, bin/hadoop fs -cat /tmp/wordcount/out/part-r-00000可以查看运行结果。

c 1 c++ 2 hadoop 2 hbase 1 helloworld 1 java 3 javascript 1 mapreduce 1 python 1
hadoop上执行mahout的bayes分类算法
这两天做了一个hadoop上跑的分类算法——贝叶斯分类。下面介绍一下实验的运行过程。。
1,获取数据集:http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz(做分类实验通常用的数据集)
2,解压数据:我的位置:/home/XXXXXX/hadoop/mahout/mahout-distribution-0.6/examples/bin/work
3,预处理训练数据集并需要把txtfile转换成sequenceFile(mahout处理的文件必须是sequenceFile格式的)。命令:mahout org.apache.mahout.classifier.bayes.PrepareTwentyNewsgroups -p /home/XXXXXX/hadoop/mahout/mahout-distribution-0.6/examples/bin/work/20news-bydate-train -o /home/XXXXXX/hadoop/mahout/mahout-distribution-0.6/examples/bin/work/bayes-train-input -a org.apache.mahout.vectorizer.DefaultAnalyzer -c UTF-8
4,将work下的bayes-train-input放到hadoop的分布式文件系统上的 20news-input。命令:hadoop dfs -put /home/XXXXXX/hadoop/mahout/mahout-distribution-0.6/examples/bin/work/bayes-train-input 20news-input
5,用处理好的训练数据集进行训练得出分类模型即中间结果。命令:mahout trainclassifier -i 20news-input -o newsmodel -type bayes -ng 3 -source hdfs
查看分类模型的内容:命令:hadoop fs -lsr /user/hadoop/newsmodel;还可以导出到本地的txt格式查看:命令:mahout seqdumper -s /user/XXXXXX/newsmodel/trainer-tfIdf//trainer-tfIdf/part-00000 -o /home/XXXXXX/hadoop/out/part-1
插入一张图片,不然显得太单调了:
6,用模型测试。命令:mahout testclassifier -m newsmodel -d 20news-input -type bayes -ng 3 -source hdfs -method mapreduce
用模型测试时还有点小错误,先这样写上,等测试成功了然后再纠正此处的错误。。见谅
Xen的基本操作
今天在做气象数据分析小实验的时候,把Xen的基本操作又重新温故了一边,现在介绍一下Xen的基本操作(ps:关于Xen的搭建以及更详细的东东,以后会陆续奉上的):
PS:一下所有的操作都是在root下进行的
1、创建虚拟机:后面的配置文件根据自己的情况而定,创建了一台dom01的虚拟机
xm create -c /home/nodes/dom01/archlinux.cfg
2、查看已经创建了的虚拟机:
xm list
3、登陆创建的虚拟机:名字根据自己的情况而定
xm console node1dom01
然后输入用户密码即可操作
4、关闭虚拟机:在此提供两种方法
一、在登陆的状态下,直接shutdown即可(推荐)
二、在主控机器上,通过远程ssh,然后shutdown关闭
三、在主控机器上,xm destroy name(根据情况而定)
PS:在此只提供最基本的操作,当然还有暂停,激活系统,调整虚拟系统所占内存大小等等。。以后用到再详述。。
SSh的RSA/DSA认证原理
几个月前就配置好了hadoop的集群,但是其中Rss密钥的问题一直不太清除,今天看了篇文章,大概知道了它的原理,分享以下。。
把公钥放在跑sshd服务的机器上,也就是:cp id_rsa.pub authorized_keys。。然后客户机上放专有密钥,ssh连接的原理是:一把专用密钥能够解锁与它相匹配的公钥,下面是连接的过程:
1、客户机发起连接 ssh user@ip。
2、sshd生成一个随机数,用公钥加密,发给客户机。
3、客户机收到这个加密数,用专用密钥解密,解密出来的随机数发给sshd。
4、sshd发现这个正确,于是同意无密码连接。
5、登录成功。
MapReduce的shuffle过程
MapReduce的核心是shuffle,她对于mapreduce的效率起到了至关重要的作用,now,我把我对shuffle的理解过程简单介绍一下,如果有误还请指教阿。。
MapReduce的过程(针对一个map来说):
每个Map在内存中都有一个缓存区,map的输出结果会先放到这个缓冲区当中,缓冲区有一个spill percent,这里默认是80%(可以手动进行配置),也就是说当输出到缓冲区中的内容达到80%时,就会进行spill(溢出),溢出到磁盘的一个临时文件中,也就是说这80%的内容成为一个临时文件,这里还涉及到了一个partition的概念,一个临时文件里面是进行了分区的,并且分区的数量由reduce的数量决定,即不同的分区内容传给不同的reduce。当这80%的内容在溢出时,map会继续向那20%的缓冲中输出。插入一点,在缓冲区溢出到磁盘之前,会进行sort和combiner,然后才会写道磁盘中。这两个步骤很重要,尤其是combiner,它直接决定了MapReduce的效率。并且sort和combiner这两个处理发生在在shuffle的整个过程中。这样一个map执行下来,就会在磁盘上存储几个临时文件,然后会对这几个临时文件进行一个merge,合并程一个文件,这个文件中有n个partition,n是reduce的数量。说明一下:这些临时文件和合并的文件都是在本地文件系统上存储的。
每个Map输出这样一个文件,最后不同Map生成的文件按照不同的partition传给不同的reduce,然后reduce直接把结果输出到HDFS文件系统上了。
这个是官方的一个图:
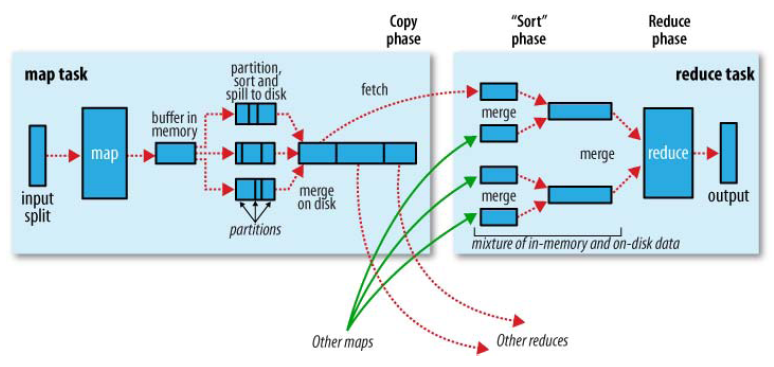
有人认为这个图有问题,但在我个人开来,这个图描述的没有问题,如果认为确实有问题的还请指教阿。。
简单说一下combiner的一个很重要的作用:combiner会对相同key的值进行合并,比如<a,1><a,1><a,1>,combiner过后合并成<a,3>,即减少了数据量,那末传向reduce的数据量就减少了,进而提高了效率。。
云计算的理解:
今天刚看到的,很有助于自己的理解: