至从C语言开始enum类型就被作为用户自定义分类有限集合常量的方法被引入到了语言当中,而且一度成为C++中定义编译期常量的唯一方法(后来在类中引入了静态整型常量)。根据上面对enum类型的描述,到底enum所定义出来的类型是一个什么样的类型呢?作为一个用户自定义的类型其所占用的内存空间是多少呢?使用enum类型是否真的能够起到有限集合常量的边界约束呢?大家可能都知道enum类型和int类型具有隐示(自动)转换的规则,那么是否真的在任何地方都可以使用enum类型的变量来代替int类型的变量呢?下面会逐一回答这些问题。
1. 到底enum所定义出来的类型是一个什么样的类型呢?
在C++中大家都知道仅仅有两种大的类型分类:POD类型和类类型(不清楚的可以参见我的其他文章)。enum所定义的类型其实属于POD类型,也就是说它会参与到POD类型的隐示转换规则当中去,所以才会出现enum类型与int类型之间的隐示转换现象。那么也就是说enum所定义的类型不具备名字空间限定能力(因为不属于类类型),其所定义的常量子具备和enum类型所在名字空间相同的可见性,由于自身没有名字限定能力,所以会出现名字冲突现象。如:
struct CEType
{
enum EType1 { e1, e2 };
enum EType2 { e1, e2 };
};
上面的例子会出现e1、e2名字冲突编译时错误,原因就在于枚举子(e1、e2)是CEType名字空间中的名字,同样在引用该CEType中的枚举子时必须采用CEType::e1这样的方式进行,而不是CEType::EType1::e1来进行引用。
2. 作为一个用户自定义的类型其所占用的内存空间是多少呢?
该问题就是sizeof( EType1 )等于多少的问题,是不是每一个用户自定义的枚举类型都具有相同的尺寸呢?在大多数的32位编译器下(如:VC++、gcc等)一个枚举类型的尺寸其实就是一个sizeof( int )的大小,难道枚举类型的尺寸真的就应该是int类型的尺寸吗?其实不是这样的,在C++标准文档(ISO14882)中并没有这样来定义,
标准中是这样说明的:“枚举类型的尺寸是以能够容纳最大枚举子的值的整数的尺寸”,同时标准中也说名了:“枚举类型中的枚举子的值必须要能够用一个int类型表述”,也就是说,枚举类型的尺寸不能够超过int类型的尺寸,但是是不是必须和int类型具有相同的尺寸呢?上面的标准已经说得很清楚了,只要能够容纳最大的枚举子的值的整数就可以了,那么就是说可以是char、short和int。例如:
enum EType1 { e1 = CHAR_MAX };
enum EType2 { e2 = SHRT_MAX };
enum EType3 { e3 = INT_MAX };
上面的三个枚举类型分别可以用char、short、int的内存空间进行表示,也就是:
sizeof( EType1 ) == sizeof( char );
sizeof( EType2 ) == sizeof( short );
sizeof( EType3 ) == sizeof( int );
那为什么在32位的编译器下都会将上面三个枚举类型的尺寸编译成int类型的尺寸呢?主要是从32位数据内存对其方面的要求进行考虑的,在某些计算机硬件环境下具有对齐的强制性要求(如:sun SPARC),有些则是因为采用一个完整的32位字长CPU处理效率非常高的原因(如:IA32)。所以不可以简单的假设枚举类型的尺寸就是int类型的尺寸,说不定会遇到一个编译器为了节约内存而采用上面的处理策略。
3. 使用enum类型是否真的能够起到有限集合常量的边界约束呢?
首先看一下下面这个例子:
enum EType { e1 = 0, e2 };
void func1( EType e )
{
if ( e == e1 )
{
// do something
}
// do something because e != e1 must e == e2
}
void func2( EType e )
{
if ( e == e1 )
{
// do something
}
else if ( e == e2 )
{
// do something
}
}
func1( static_cast<EType>( 2 ) );
func2( static_cast<EType>( -1 ) );
上面的代码应该很清楚的说明了这样一种异常的情况了,在使用一个操出范围的整型值调用func1函数时会导致函数采取不该采取的行为,而第二个函数可能会好一些他仅仅是忽略了超出范围的值。这就说明枚举所定义的类型并不是一个真正强类型的有限常量集合,这样一种条件下和将上述的两个函数参数声明成为整数类型没有任何差异。所以以后要注意标准定义中枚举类型的陷阱。(其实只有类类型才是真正的强类型)
4. 是否真的在任何地方都可以使用enum类型的变量来代替int类型的变量呢?通过上面的讨论,其实枚举类型的变量和整型变量具有了太多的一致性和可互换性,那么是不是在每一个可以使用int类型的地方都可以很好的用枚举类型来替代呢?其实也不是这样的,毕竟枚举类型是一个在编译时可区分的类型,同时第2点的分析枚举类型不一定和int类型具有相同的尺寸,这两个差异就决定了在某些场合是不可以使用枚举类型来代替int类型的。如:
第一种情况:
enum EType { e1 = 0, e2, e3 };
EType val;
std::cin >> val;
第二种情况:
enum EType { e1 = 0, e2, e3 };
EType val;
std::scanf( "%d", &val );
上面的两种情况看是基本上属于同一种类型的问题,其实不然。第一种情况会导致编译时错误,会因为std::cin没有定义对应的枚举类型的重载>>运算符而出错,这就说明枚举类型是一种独立和鉴别的类型;而第二种情况不会有任何编译时问题,但是可能会导致scanf函数栈被破坏而使得程序运行非法,为什么会这样呢?上面已经分析过了枚举类型变量的尺寸不一定和int类型相同,这样一来我们采用%d就是说将枚举类型变量val当作4字节的int变量来看待并进行参数压栈,而在某些编译器下sizeof( val )等于1字节,这样scanf函数就会将val变量地址中的后续的三字节地址也压入栈中,并对其进行赋值,也许val变量后续的三个字节的地址没有特殊含义可以被改写(比如是字节对齐的空地址空间),可能会认为他不会出现错误,其实不然,在scanf函数调用结束后会进行栈清理,这样一来会导致scanf函数清理了过多的地址空间,从而破坏了外围函数的栈指针的指向,从而必然会导致程序运行时错误。
由上面的说明枚举类型有那么多的缺点,那我们怎样才能够有一个类型安全的枚举类型
呢?其实可以采用类类型来模拟枚举类型的有限常量集合的概念,同时得到类型安全的好处,
沙诺 Blog
Happy coding
shanuo
分类
最新评论
最新留言
链接
RSS
功能
选择排序(C实现)
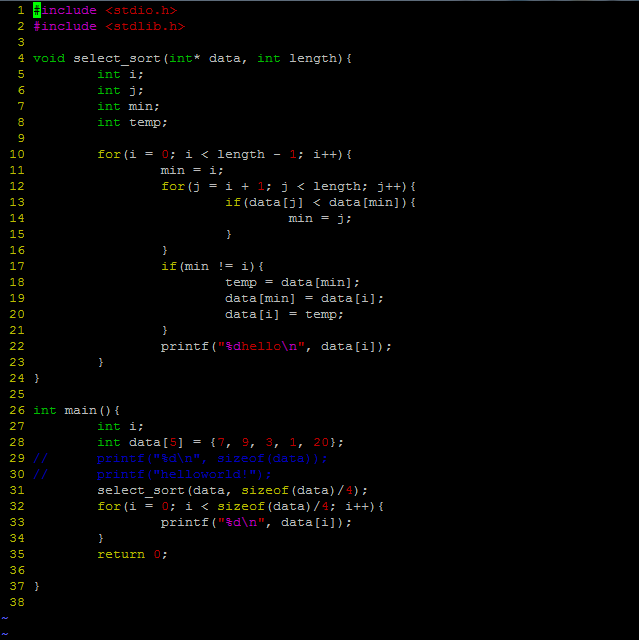
程序很简单,但是有些小细节:
1、sizeof(data):取到的是字节数,还要除以4才能得出元素个数。。
2、设置变量min记录数组下标,而不要频繁的交换。。
各种排序陆续送上。。
Xen的基本操作
今天在做气象数据分析小实验的时候,把Xen的基本操作又重新温故了一边,现在介绍一下Xen的基本操作(ps:关于Xen的搭建以及更详细的东东,以后会陆续奉上的):
PS:一下所有的操作都是在root下进行的
1、创建虚拟机:后面的配置文件根据自己的情况而定,创建了一台dom01的虚拟机
xm create -c /home/nodes/dom01/archlinux.cfg
2、查看已经创建了的虚拟机:
xm list
3、登陆创建的虚拟机:名字根据自己的情况而定
xm console node1dom01
然后输入用户密码即可操作
4、关闭虚拟机:在此提供两种方法
一、在登陆的状态下,直接shutdown即可(推荐)
二、在主控机器上,通过远程ssh,然后shutdown关闭
三、在主控机器上,xm destroy name(根据情况而定)
PS:在此只提供最基本的操作,当然还有暂停,激活系统,调整虚拟系统所占内存大小等等。。以后用到再详述。。
enum类型的本质(转)
SSh的RSA/DSA认证原理
几个月前就配置好了hadoop的集群,但是其中Rss密钥的问题一直不太清除,今天看了篇文章,大概知道了它的原理,分享以下。。
把公钥放在跑sshd服务的机器上,也就是:cp id_rsa.pub authorized_keys。。然后客户机上放专有密钥,ssh连接的原理是:一把专用密钥能够解锁与它相匹配的公钥,下面是连接的过程:
1、客户机发起连接 ssh user@ip。
2、sshd生成一个随机数,用公钥加密,发给客户机。
3、客户机收到这个加密数,用专用密钥解密,解密出来的随机数发给sshd。
4、sshd发现这个正确,于是同意无密码连接。
5、登录成功。
MapReduce的shuffle过程
MapReduce的核心是shuffle,她对于mapreduce的效率起到了至关重要的作用,now,我把我对shuffle的理解过程简单介绍一下,如果有误还请指教阿。。
MapReduce的过程(针对一个map来说):
每个Map在内存中都有一个缓存区,map的输出结果会先放到这个缓冲区当中,缓冲区有一个spill percent,这里默认是80%(可以手动进行配置),也就是说当输出到缓冲区中的内容达到80%时,就会进行spill(溢出),溢出到磁盘的一个临时文件中,也就是说这80%的内容成为一个临时文件,这里还涉及到了一个partition的概念,一个临时文件里面是进行了分区的,并且分区的数量由reduce的数量决定,即不同的分区内容传给不同的reduce。当这80%的内容在溢出时,map会继续向那20%的缓冲中输出。插入一点,在缓冲区溢出到磁盘之前,会进行sort和combiner,然后才会写道磁盘中。这两个步骤很重要,尤其是combiner,它直接决定了MapReduce的效率。并且sort和combiner这两个处理发生在在shuffle的整个过程中。这样一个map执行下来,就会在磁盘上存储几个临时文件,然后会对这几个临时文件进行一个merge,合并程一个文件,这个文件中有n个partition,n是reduce的数量。说明一下:这些临时文件和合并的文件都是在本地文件系统上存储的。
每个Map输出这样一个文件,最后不同Map生成的文件按照不同的partition传给不同的reduce,然后reduce直接把结果输出到HDFS文件系统上了。
这个是官方的一个图:
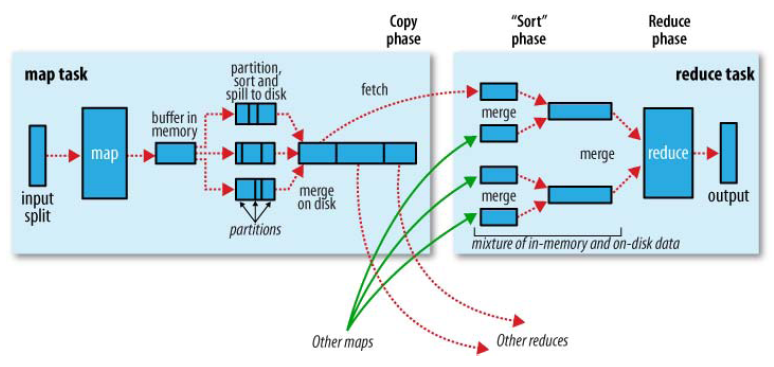
有人认为这个图有问题,但在我个人开来,这个图描述的没有问题,如果认为确实有问题的还请指教阿。。
简单说一下combiner的一个很重要的作用:combiner会对相同key的值进行合并,比如<a,1><a,1><a,1>,combiner过后合并成<a,3>,即减少了数据量,那末传向reduce的数据量就减少了,进而提高了效率。。
qq的通信实现
今天写了一个qq间的UDP套接字通信,感觉UDP的要简单些,分享一下:
代码如下:
1、客户端
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <errno.h>
4 #include <string.h>
5 #include <sys/types.h>
6 #include <netinet/in.h>
7 #include <sys/socket.h>
8
9 #define SERVER_PORT 8003
10 #define MSG_BUF_SIZE 512
11 int port = SERVER_PORT;
12
13
14 int main(){
15 int sockfd;
16 int count = 0;
17 int flag;
18 char buf[MSG_BUF_SIZE];
19 struct sockaddr_in address;
20 sockfd = socket(AF_INET,SOCK_DGRAM,0);
21 if(sockfd == -1){
22 fprintf(stderr,"socket error");
23 exit(1);
24 }
25 memset(&address,0,sizeof(address));
26 address.sin_family = AF_INET;
27 address.sin_addr.s_addr = inet_addr("server");
28 address.sin_port = htons(port);
29 flag = 1;
30 do
31 {
32 sprintf(buf,"Packet %dn",count);
33 if(count > 30){
34 sprintf(buf,"overn");
35 flag = 0;
36 }
37 sendto(sockfd,buf,sizeof(buf),0,(struct sockaddr *)&address,sizeof(address));
38 count++;
39 }
40 while (flag);
41 // printf("%d\n",MAXFILE);
42
43 return 0;
2、服务器端
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <errno.h>
4 #include <string.h>
5 #include <sys/types.h>
6 #include <netinet/in.h>
7 #include <sys/socket.h>
8
9 #define SERVER_PORT 8003
10 #define MSG_BUF_SIZE 512
11
12 int port = SERVER_PORT;
13 char *hostname = "127.0.0.1";
14
15 int main(){
16 int sinlen;
17 char message[MSG_BUF_SIZE];
18 int sockfd;
19 struct sockaddr_in sin;
20 struct hostent *server_host_name;
21 sockfd = socket(PF_INET,SOCK_DGRAM,0);
22 if(sockfd == -1){
23 fprintf(stderr,"socket error");
24 exit(1);
25 }
26 server_host_name = gethostbyname("127.0.0.1");
27 bzero(&sin,sizeof(sin));
28 sin.sin_family = AF_INET;
29 sin.sin_port = htons(port);
30
31 if((bind(sockfd,(struct sockaddr *)&sin,sizeof(sin)))== -1){
32 fprintf(stderr,"bind error");
33 exit(1);
34 }
35 while(1){
36 sinlen = sizeof(sin);
37 recvfrom(sockfd,message,256,0,(struct sockaddr *)&sin,&sinlen);
38 printf("nData come from server:n%sn",message);
39 if(strncmp(message,"over",4)==0)break;
40 }
41 close(sockfd);
42 return 0;
43 }
这个程序还留下一个问题:我想让我们实验室中任意两台机器都可通信还没实现,只能在自己的机器上进行通信,放一放,过后几天解决, 还有其它任务。
最后简单做一下UDP与TCP的比较:
1、udp的服务器端只需要socket,bind就ok了,而tcp需要完整的四步。
2、udp的客户端不需要连接(用了也不会出错),socket之后直接通信即可。
OK,国庆长假结束。。
守护进程
今天写了一个简单的守护进程,算是网络编程入一下门吧
首先还是把创建守护进程的步骤写一下(5步):
1、fork()调用,创建子进程,父进程退出(这样是子进程成为一个orphan progress,进而由init进程托管)
2、调用setsid(),创建一个新的进程组,新的会话组,担任该会话组的组长,并脱离终端。(此处有疑问,还请高手解释)
3、改变当前目录的根目录,chdir();
4、重设文件权限掩码,umask(0);
5、关闭不在需要的文件描述符,close()。
接下来是代码部分:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/wait.h>
#include <syslog.h>
#define MAXFILE 65535
int main(){
pid_t pc,sid;
int i,fd,len;
char *buf = "This is a Daemon\n";
len = strlen ( buf );
pc = fork();
if( pc < 0 ){
printf("error fork\n");
exit(1);
}
else if( pc > 0 ){
exit(0);
}
openlog("update_daemon",LOG_PID, LOG_DAEMON);
sid = setsid();
if(sid < 0){
syslog(LOG_ERR,"%s\n","setsid");
exit(1);
}
sid = chdir("/");
if(sid < 0){
syslog(LOG_ERR,"%s\n","chdir");
exit(1);
}
umask(0);
for(i=0; i<MAXFILE; i++){
close(i);
}
fd = open("/home/shanuo/yang.log",O_CREAT|O_WRONLY|O_APPEND,0600);
while(1){
if(fd < 0){
syslog(LOG_ERR,"open");
exit(1);
}
write(fd,buf,len+1);
sleep(5);
}
close(fd);
closelog();
// printf("%d\n",len);
return 0;
}
这个代码是带出错处理的:采用系统日志的方式。
史上最牛逼的java代码
史上最牛逼的java代码
package socket;
public class 牛逼人 {
public void 我真牛逼阿(){
System.out.println("不牛逼不行阿");
}
public static void main(String[] args) {
牛逼人 牛逼人 = new 牛逼人();
牛逼人.我真牛逼阿();
}
}
注:eclipse编译通过的。。哈哈
c中产生随机数的方法
c中产生随机数可以结合srand()和rand()两个函数,这两个函数都是在标准库 stdlib.h 中。
srand()函数可以初始化种子,种子的概念在此简单说一下,产生一个随机数要有一个最开始的值,然后随机数就是根据这个值算出来的,这个原始的值就是种子,所以只要我们的种子不同,产生的随机数就不同。因此我们一般以当前时间作为种子。具体用法如下:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <time.h>
4 int main()
5 {
6 srand((unsigned)time(NULL));
7 printf("Random number in the 0-100 range: %d\n", rand()%101);
8 return 0;
9 }
这样我们就可以产生0-100 的随机数了。
Windows开机破解密码小技巧
1 开机进入安全模式,然后修改用户密码即可。
2 开机进入系统到选择用户界面时,按Ctrl+alt+delete, 进入管理员用户登陆界面,用户输入administrator, 密码一般为空。 然后进入系统,即可修改 用户密码。